
Debiasing Science: The best way to overcome the replication crisis is to simply require replication to fully establish new findings
Why and how this simple idea could work well to reduce scientific bias

This post is the first in a series focused on scientists’ biases, written mostly with other scientists in mind (but still of interest to anyone interested in science!)
In brief: In scientists’ efforts to make new discoveries many decisions must be made, all biased by scientists’ desire to get significant results. This has led to a replication crisis, in which many scientific results do not replicate – a basic requirement of a scientific finding being true. Many complex solutions to this problem have been suggested. I suggest a seemingly straightforward solution: simply requiring replication of a finding prior to it being accepted as fully established knowledge. Here I describe how this challenging way out of the replication crisis could work well in practice, including my own attempts to replicate my lab’s cognitive neuroscience results.
The entire point of science is to find out what is empirically true. It's not to share interesting ideas, not to publish papers, not to impress your friends. So it's a big problem when many (potentially most) scientific studies don't replicate – a basic requirement of a scientific finding being true. This "replication crisis" has been shown in multiple fields, such as psychology (Shrout and Rodgers, 2018), neuroscience (Barch and Yarkoni, 2013), and biomedicine (Kaplan and Irvin, 2015). This is likely an issue in all scientific fields (except perhaps areas of physics or chemistry with extremely low noise in their data), whether it’s been acknowledged or not.
I've been thinking about this problem for over a decade now, and I think I have the start of a solution. It may seem too obvious, but in brief, the idea is to simply require a study to be replicated prior to its findings being accepted as fully established knowledge.
This is such a simple idea that I obviously can’t say it’s my idea. What I contribute here is primarily an argument (and evidence) for why and how this simple idea could work well in practice.
In short, I argue that setting replication as a standard for fully establishing scientific knowledge would substantially improve the incentive structure in scientific practice, resulting in pooling of resources into a smaller number of studies. This would improve scientific progress by making each study higher quality and more conclusive while simultaneously making it easier to keep up on the literature by reducing the overall number of studies.
But before I go into the meat of my idea: Since we’ve known about this problem since at least 2010 (perhaps as early as 1974), what has already been done to try fixing it? In psychology there has been a push to pre-register studies. The idea is that the major cause of failures to replicate is the large number of "experimenter degrees of freedom" during data analysis (see Figure 1), which increase the odds of false positives (i.e., results that won't replicate). Intuitively, this results from looking at many aspects of the data in many different ways until something is "significant" (p<0.05), which is virtually guaranteed to happen even in purely random data if enough comparisons are made (Kriegeskorte et al., 2009). Pre-registering involves publicly sharing a plan for data collection and analysis, which the experimenters must stick to. This reduces experimenter degrees of freedom (number of multiple comparisons; see Figure 1), supposedly increasing the replicability of results. It's still possible to report unplanned data analyses, but they need to be labeled "exploratory" to reflect that they do not have the benefits of the pre-registered analyses. There's evidence that pre-registration works to reduce false positives in psychology (Scheel et al., 2021) and biomedical clinical trials (Kaplan and Irvin, 2015).

Figure 1 – Hypothetical study involving excessive experimenter degrees of freedom and an experimenter motivated to get a significant result. Each data analysis decision is a degree of freedom. The experimenter identifies a significant result in Dataset 1 (false positive due to overfitting to noise), then has the freedom to do the same thing in Dataset 2. This is unlikely to be a case of misconduct: The decisions leading to the false positive were likely driven by unconscious biases toward a rewarding outcome, and they are likely present for all of us human scientists. This “false replication” could be avoided by using the split-half lock-box approach (in red). This involves splitting the data in two halves with the second half left untouched (in a “lock box”) until the end. The first half is analyzed freely, then identical analyses are run on the second half of data.
So, why not just use pre-registration, rather than requiring replication? It's because pre-registration 1) restricts creativity/flexibility in fields that benefit from extensive creativity/flexibility due to high complexity and many unknowns (e.g., neuroscience and psychology), 2) doesn’t completely fix the problem of experimenter degrees of freedom because most pre-registrations are (probably necessarily) overly vague on procedures, and 3) isn't able to help increase replicability of the creative/flexible (exploratory) analyses that almost inevitably occur even in pre-registered studies. Basically, pre-registration isn't good enough to fix the replication crisis when there's high complexity and high uncertainty (i.e., a lot left to discover), as is the case in most areas of science.
This is where requiring replication comes in to save the day!
Simply requiring a finding to replicate gives all the benefits of pre-registration and more. It allows for full data collection and analysis flexibility in a "discovery" dataset, with a second "replication" dataset (collected and analyzed identically to the exploratory dataset) to confirm the results. Essentially, this approach has pre-registration (without analytical vagueness) built in while allowing for full data analysis flexibility.
Some studies have already demonstrated that this approach can work. The ones I'm familiar with tend to use large public datasets, likely since all that needs to be done is to split the dataset in two halves and – once all exploratory analyses are finalized on the first half – re-run the exact same analysis (i.e., same analysis code) on the second half. For example, my lab has done this in Ji, Spronk, et al. (2019), Cole et al. (2021), and McCormick et al. (2022). I follow others in calling this the split-half lock-box replication approach.
But is within-study replication a realistic standard for new datasets collected by small labs? What about expensive data collection like fMRI?
Well, I run a small lab and collect expensive data (fMRI), and my group was able to do this. So, it is feasible. I did have a grant (usually necessary for fMRI data collection anyway), and I did reduce the number of experiments run relative to what is typical for this type of a grant in order to increase the number of participants in a single dataset. However, because we were able to test for replication within a single study, the quality of the science resulting from the work was boosted by reducing the number of studies performed with the grant funds.
The study in question is Cocuzza et al. (2020). Central to the proposed intention to replicate novel findings, we worried quite a bit about statistical power for typical effect sizes in the field, leading us to collect much more data than is typical. Specifically, we collected fMRI data with 100 participants for this single dataset, rather than the more typical approach of collecting ~30 participants per dataset (for within-subject statistical designs). This reduced the number of studies we could do, but led to higher quality studies. Quality over quantity! [Note that we actually did get several studies out of this complex dataset by using it to test multiple distinct hypotheses, so it may have been more like "quality and quantity".]
The Cocuzza et al. (2020) study made full use of the proposed split-half lock-box approach: 50 participants were selected as the "discovery" dataset and the other 50 were in the "replication" dataset. The replication dataset was put in a "lock box" such that we did not peek at the replication dataset results until the exploratory analyses were finalized.
Why so many participants per split half? The strong incentive to replicate drove our sample size up within each split-half. If we needed to replicate our result to establish a finding we needed to increase the likelihood that we would find a result of interest in each of the split halves. A quick statistical power analysis reveals that a sample size of at least 44 is needed to achieve 90% power (chance of seeing an effect, p<0.05), assuming a medium effect size (dz=0.5) in a within-subjects design. So, we were sufficiently motivated to get a sample size above that number, since even going to 90% power seemed dicey when the very viability of our results depended on it. (Note that, for whatever reason, most power analyses set power to only 80%.)
So what happened? We were able to carry out a complex set of analyses involving multiple novel analytical measures (i.e., extensive experimenter degrees of freedom) and multiple comparisons, while retaining the primary benefits of pre-registration. Note that we did think of experimenter degrees of freedom (and other forms of multiple comparisons) as a problem, but we were properly incentivized to minimize them not just out of moral obligation to Science (as is typical) but also out of the practical motivation of wanting the findings to actually replicate in the other split-half dataset. Specifically, we avoided trying many possible novel analytical measures and we minimized other forms of multiple comparisons when possible. Thus, requiring (or at least putting large value in) replication created an ideal incentive structure for good scientific practices.
Cocuzza et al. (2020) was also an example of cross-study replication: We replicated the main results from my previous study Cole et al. (2013). Briefly, Cole et al. (2013) established the existence of flexible hubs within the frontoparietal network (FPN) in the human brain, suggesting a mechanism by which the human brain implements task flexibility. Note that it was in some sense a "conceptual replication" in that the stimuli and overall cognitive paradigm were somewhat distinct between studies. This is good in that it suggests the Cole et al. (2013) results generalize, but potentially bad because a completely new data analysis allowed for uncontrolled experimenter degrees of freedom that may have led to false positives. Importantly, we also replicated the replication! Our use of split-half lock-box replication strengthened our replication by showing it worked even when all experimenter degrees of freedom were eliminated (in the replication split-half dataset).
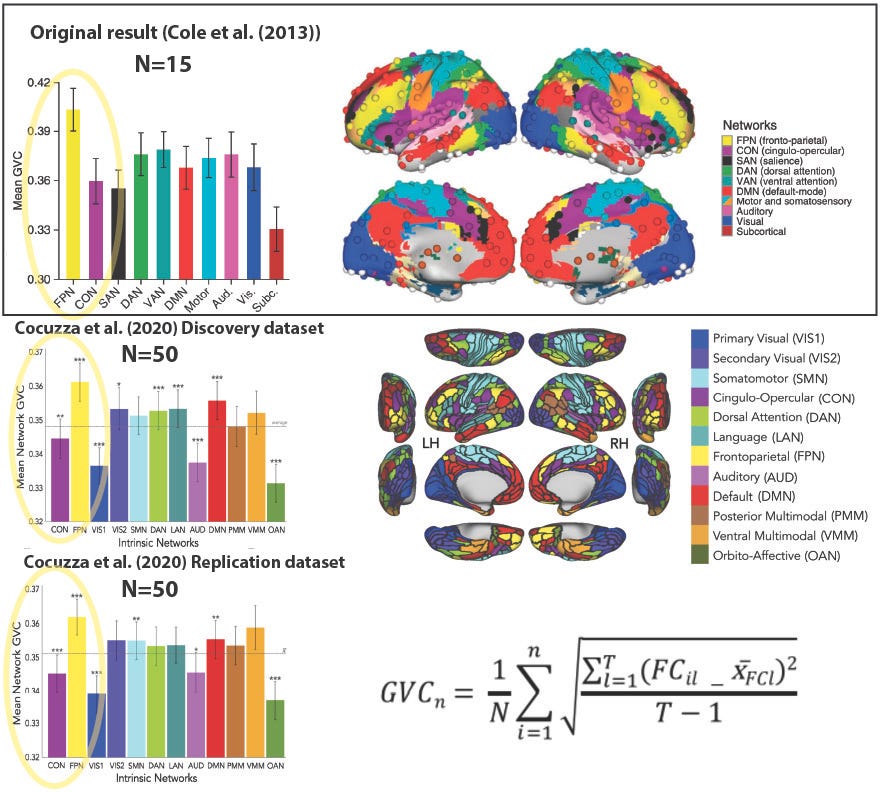
Figure 2: Replication of prior study is strengthened by additional within-study replication. Top: The Cole et al. (2013) result involving global variability coefficient (GVC) (left) with the Power et al. (2011) brain network partition (right). The primary result was the fronto-parietal network (FPN) having significantly higher GVC than the cross-network mean, and the cingulo-opercular network (CON) in particular (p<0.05). Bottom: Replication of Cole et al. (2013) result by Cocuzza et al. (2020), with improved network partition. This new network partition is an experimenter degree of freedom, along with hundreds of other data analysis decisions! Thus, while informative, the Discovery dataset replication of Cole et al. (2013) may be a false positive due to overfitting to the data (e.g., from unintentional/unconscious cognitive biases toward "getting a result" by the data analyst). The Replication dataset (bottom left) – independent data analyzed identically to the Discovery dataset – solidifies the "conceptual" replication in the Discovery dataset. Bottom right: The GVC graph theoretical measure used in this analysis, which estimates global task-state functional connectivity changes across task states; see Cole et al. (2013) and/or Cocuzza et al. (2020) for details.
Until the scientific community requires replication for a finding to be fully established there will not be enough incentive for individual scientists to put in the effort to replicate their results. Indeed, until replication is highly valued by the scientific community there is a disincentive to attempt replication, since it takes additional work (and funds) and can possibly invalidate hard-won new results.
So was all the effort to replicate results in Cocuzza et al. (2020) worth it? From a purely scientific perspective, obviously yes. However, so far I have been disappointed with the value of this from a "science career" perspective. While our study has been well received (see here), I have seen no indication that this is due to the very solid results established via replication. (Please let me know in the comments if you think I'm mistaken on this!)
I think studies that include replications should stand out as having an extra "gold star" ⭐️ that make them pop out relative to similar studies without replications. How can we make this happen? Please share your thoughts in the comments. One thought I have is to create a database of within-study replicated findings, to be used as complementary to scientific impact metrics like citation count.
Ultimately, however, what we need is a shift in social norms in science toward replication and strongly valuing replications when we see them.
Should within-study replication always be required as a standard in science?
If the data are sufficient for doing a split-half lock-box replication (e.g., large public datasets, online behavioral data collection) I think this should be absolutely required for peer-reviewed publication.
For more expensive data collection situations, especially for small labs, split-half lock-box replication should be a huge bonus, but not required for peer-reviewed publication. However, in the absence of (perhaps highly detailed) pre-registration, the results should be considered somewhat preliminary, with a call in the Discussion section for replication in future studies to fully establish the reported findings.
Some relevant biases here
A major theme of this newsletter is the impact of cognitive biases on human thought and behavior. In this case, I think the incentive structure in scientific practice is biasing scientists away from pursuing replication. This is despite replication supporting the very thing science is trying to optimize: the veracity of findings.
The primary incentive behind this bias away from replication is likely the desire to get significant results. This is intrinsic to scientific practice, so we must live with it and try our best to reduce negative side effects of this bias. However, the pressure to publish often exacerbates this bias. If we more strongly valued quality over quantity in our work we could perhaps reduce this bias for the good of scientific progress. Further, reducing the number of publications while increasing their quality would be great for the scientific literature, given how difficult it has become to 1) filter the literature for quality and 2) keep up on the literature given its quantity.
Another bias – the sunk cost fallacy – likely drives many away from replication attempts, since so much work has been put into getting the exploratory findings. This is problematic, however, since the entire point of science is empirical truth, and no matter how much effort has been expended, reporting a false result as true sets us all back. (From a personal perspective, what was the point of all that work if all you did was make science and human knowledge worse?)
Still, assuming we could somehow achieve the same scientific quality, it would be more optimal (i.e., rational) to not have to spend the time and resources to collect double the data and perform replication analyses. If scientific standards eventually improve and we see that virtually every finding replicates, then I think it would be reasonable to increase our efficiency by only replicating the most controversial results (i.e., those least consistent with the rest of the literature). In the meantime, however, without replication we do not have the evidence of quality that is so important for knowing that any given finding is truly true.
What needs to change to make within-study replication the norm?
Some suggestions…
Journal reviewers and editors: Should start strongly valuing within-study replications, requiring them when they are reasonable to request (e.g., when large public datasets are used), and generally taking them into account as a major factor in competitive journals
Grant reviewers: Should start counting plans for within-study replications as highly competitive, pushing applicants toward using them, while keeping in mind the need to reduce the number of studies in such grant applications (to achieve sufficiently large sample sizes)
Hiring & promotion committees: Should start strongly valuing replication studies generally, including within-study replication studies, making it more feasible for scientists to spend substantial resources to ensure the quality of their findings
Thoughts? Please share in the comments!
Here’s a comment on this post originally put on Facebook, by Daniel Handwerker (copied here with permission). See next comment for my reply…
“I disagree.
You say the goal of science is to understand what can be "accepted as fully established knowledge" You do not claim or explain why that goal has to be reached to publish a peer reviewed article. I'd go father and say, if the criteria for publication is that the reviewers thinks a finding should be accepted as established knowledge, then nothing would ever get through peer review. A replication might increase the likelihood a finding is reliable but it wouldn't remotely cross the high bar you're setting.
Replication, particularly the split half replications you're using in examples, only focus on two causes of irreproducibility: Statistical power & methodological clarity/processing consistency. It might help in some situations, but won't fundamentally change the core issues underlying seeking truths about a complex system.
This is still my favorite piece on this topic: https://drugmonkey.scientopia.org/2014/07/08/the-most-replicated-finding-in-drug-abuse-science/ The core message is that publishing and sharing inconsistent findings from the fundamentally same study design is what advanced scientific understanding. This example isn't a replication failure, it's advancing science through conversations on why things aren't replicating.
Fundamentally, the question is what is a peer reviewed scientific publication? If we treat scientific publications as markers of scientific truth, then we have a replication crisis every time the findings in a specific paper aren't replicated. If we treat scientific publications as part of a conversation that advances science, then the purpose of each paper should be to clearly explain what they did (so that others replicating is possible), explain why their results are plausible (i.e. statistics & methods are sufficiently robust to support claims), and limitations on their interpretations of results. Some papers might present more support for their interpretation and some might present an interesting observation paired with clear discussion of interpretability limits. Both are critical parts of scientific discourse and advancement.
There are two core trouble with the goal of making every publication reproducible. 1. It's impossible and claiming it is possible is unscientific. 2. It amplifies the file drawer effect where potentially valuable non-replications never enter scientific discourse.”