


Debiasing Science: Toward the creation of an Evidence Quality Index (EQI)
A metric with the potential to reduce bias in science and (through better science communication) society

In brief: Scientists are biased by imperfect metrics of success, such as the number of citations their publications receive. I propose creation of a science quality metric – the Evidence Quality Index (EQI) – that aspires to quantify the things that scientists should be biased toward. These are things like the robustness of reported findings (e.g., due to replication) and the conclusiveness of those findings. Presenting an EQI value with each study would have many benefits. Readers would rapidly get an estimate of a study’s quality prior to reading it, while scientists would get quantifiable credit for the quality of their work. Here I make an initial attempt at creating an EQI.
I recently posted an idea for how to improve the quality of science going forward: simply require replication prior to deciding a finding is fully established. The core idea is that scientists are necessarily biased toward getting clear (statistically significant) results, biasing decision making toward overfitting their data to noise, especially for complex data analyses. Simply requiring (or more strongly valuing) replication of results was proposed as a way to help correct the incentive structure to reduce this bias. Not everyone agreed with me that replication should be necessary for a finding to be fully established, but it seemed we could all agree that replication increases the quality of a study.
What is unclear is what I meant by a finding being “fully established”.
All I know is that there are some findings that scientists generally consider fully established – like climate change, the existence of influenza, and evolution by natural selection – and it has something to do with the quality of science supporting those findings. It would be very useful if we had a way to quantify the scientific quality that can eventually lead to a finding being fully established. We could call this the Evidence Quality Index (EQI). Perhaps we could even use it to formally define what it means for a finding to be “fully established”! We could call it the “fully established” threshold.
Much more exciting than this, however, is the possibility of defining an EQI that can rapidly give readers an estimate of a study’s quality prior to reading it. This could potentially solve many current problems in scientific practice.
First, an EQI would be very useful for science communication – both with non-scientists and scientists in other fields. This could be one more tool against science misinformation, for instance, since a stronger study (e.g., involving randomized controlled experimentation) invalidating a belief (e.g., that vaccines cause autism) could be easily seen as more conclusive than a prior weaker study (e.g., involving observational data) driving that belief. More generally, this could lead to a more scientifically informed public.
Second, an EQI could be extremely helpful for scientific literature curation. This could make it easier for scientists to keep up on the literature, by providing an easy summary of the conclusiveness of a study while deciding whether to read it.
Third, an EQI would improve the incentive structure for scientists by giving them quantifiable credit for the quality of their work. This contrasts with the current “publish or perish” system, in which the number of publications and the number of citations of those publications are the primary metrics driving scientists. This has distorted science by pressuring scientists toward quantity over quality of studies, while over-hyping those low-quality studies to try to get more citations/impact. Adding an EQI to the mix would shift scientific incentives back toward scientific quality, to the benefit of both scientists and science.
Finally, having an EQI would complement the “safe guard” provided by peer review by having it be more than a binary outcome. Instead, the binary outcome would be complemented by a peer review-approved EQI score composed of a series of informative sub-scores. (Publicly released peer reviews could also help here, though those would be useful primarily for experts in the study’s subfield.) Improving the outcome of peer review is all the more important given that some have recently questioned the value of peer review.
Is an effective EQI even possible?
An EQI seems simple in the abstract, but creating an effective EQI is an extremely hard problem.
How do I know? Part of my day job is to create graph theory metrics quantifying brain interaction dynamics (see here and here), which is already difficult – my attempts to create an EQI have been even more so. I think this will become clear when I describe my thoughts on what an EQI could look like.
To make an EQI tractable let’s focus solely on empirical observations – quantifying the evidence for a finding/claim – rather than theoretical interpretation of findings. Thus, we’d assign an EQI value (e.g., 60.5) to a study’s claim that drinking water through a straw cures hiccups. We would not assign an EQI based on the study’s proposed theory for why drinking through a straw cures hiccups. This is because I can’t think of a way to quantify the relationship between observations and support for a hypothesis (especially when there are many alternatives) that could allow apples-to-apples comparison across studies, but let me know if you can think of a way this could work. For now, I think a simple binary prerequisite evaluating whether “empirical observations align with theoretical claims” (as verified by peer reviewers) will have to do.
Some other desirable properties for an EQI: 1) a normalized scale – I’m thinking 0 to 100 with one decimal point precision, 2) a versioning system to allow for updates to the scale as it is refined, and 3) since most empirical claims can be described in terms of causal inference (e.g., causal impact on the scientist’s retina is present even for pure visual observation), the strength of causal inference (e.g., as described in The Book of Why) should be the biggest factor in the EQI value.
Having a versioning system helps us here, since we can use current worst vs. best practices as the bottom and top of the scale, respectively. With regard to causal inference, the worst practice that most would still say is scientific could look something like: 1) a very small amount of data (low statistical power), 2) personal observations (scientist’s own percepts, no intervention), 3) no control group, 4) no accounting for likely confounds, 5) non-representative sample (e.g., only college students of a single race and gender in a study when the target inference is all humans), 6) no replication of results, and 7) no correction for multiple comparisons (despite over 10 comparisons made). Such a study would get a 0, while the opposite answer for each of the 7 criteria would give a score of 100. For the non-binary criteria (#1 and #2), I’ll set for now these best practices: 1) A very large amount of data relative to most similar studies (e.g., over 1,000 subjects for human psychology and neuroscience studies), and 2) a double-blind randomized controlled trial/intervention study design (or within-subject randomized controlled design if possible). For now, let’s just assign 1/7 of the EQI value equally to each of the 7 criteria.
Note that the first step, prior to evaluating the 7 criteria above, would be to answer the prerequisite criterion: Do empirical observations align with theoretical claims? If the answer is “no” then no EQI value can be assigned (it is automatically assigned N/A).
What might the EQI look like in practice?
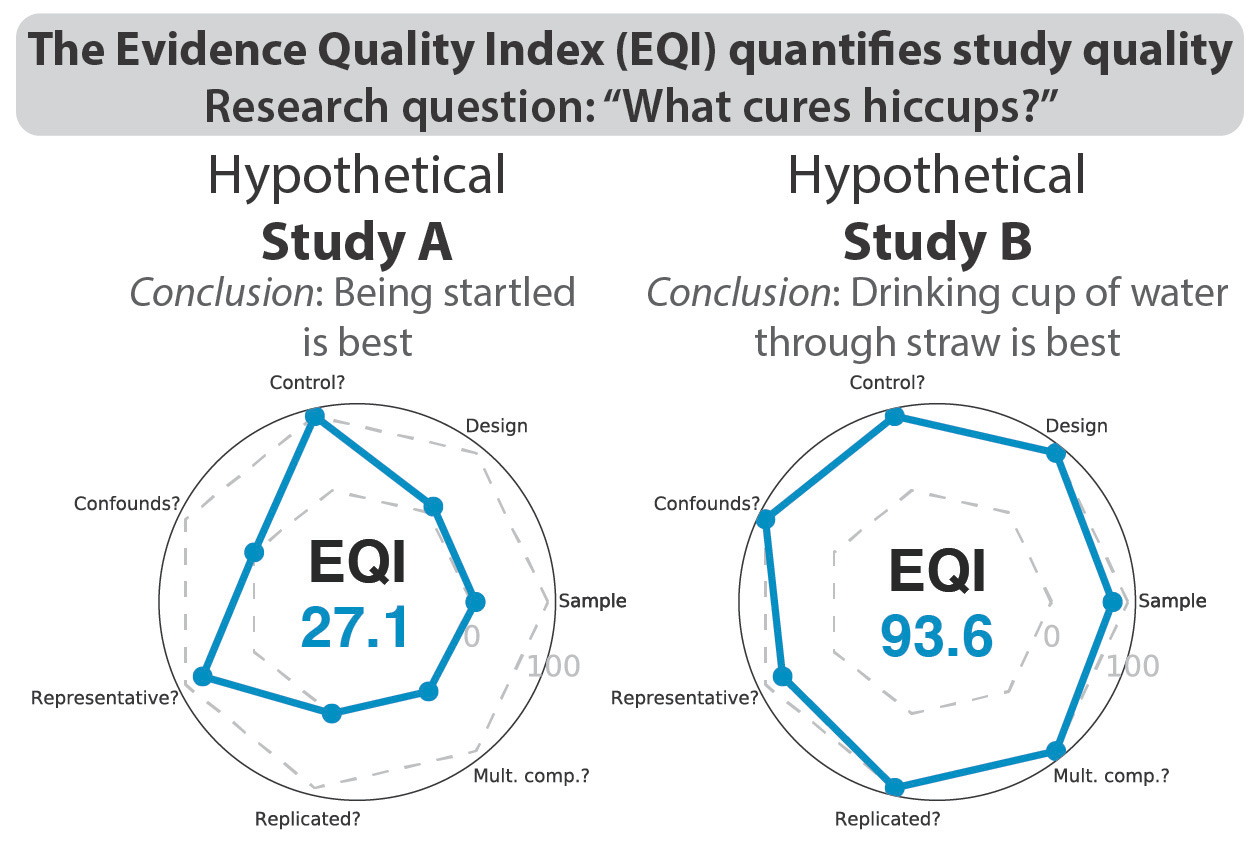
Continuing with the “what cures hiccups” example, let’s imagine two studies and try to assign an EQI to each. Study A is purely observational, with 50 participants self-reporting in a survey what strategy they tried last time they had hiccups and whether it stopped the hiccups. The study reported a significant (p<0.05) relationship between being surprised by someone and hiccup cessation, with no other significant relationship reported. The EQI results are illustrated on the left side of the figure (above), in addition to being described below.
To the prerequisite question (“Do empirical observations align with theoretical claims?”) we answer yes.
Going through the 7 EQI criteria:
1) ideally we’d base the sample size on statistical power but (as with all novel research) we don’t know the effect size beforehand, so we go with S1=100*(50/1000) = 5
2) it’s observational (S2=10)
3) there’s a control group (individuals who used an alternative strategy) (S3=100)
4) there is no consideration of potential confounds, such as the confound of the passage of time (hiccups could go away on their own) (S4=0)
5) the sample was fairly representative since an online sample was used (large ranges for age, race, sex, geographical location), but clearly not fully representative of the whole of humanity since it was only those with an internet connection looking to make money filling out surveys (S5=75)
6) results were not replicated with independent data within the study (S6=0)
7) results were corrected for multiple comparisons, but using false discovery rate (rather than Bonferroni or permutation testing) (S7=80)
Study A’s EQI: (5+10+100+0+75+0+0)/7 = 27.1
In contrast, hypothetical Study B was a large randomized controlled trial funded to (hopefully) scientifically establish how humans can rapidly eliminate annoying hiccups, increasing comfort for all 8 billion of us. Three strategies were tested for any hiccups that participants experienced within a 6 month period (one strategy randomly assigned to each participant): 1) rapidly drinking an entire 8 oz of water at once without a straw, 2) rapidly drinking an entire 8 oz of water at once with a straw, 3) having the participant ask someone to startle the participant by clapping loudly from behind. The study reported a significant (p<0.05) relationship between rapidly drinking an entire 8 oz of water at once with a straw and hiccup cessation (strategy #2), with no other significant relationship reported, and a significantly (p<0.05) stronger relationship for strategy #2 than each of the other strategies. The EQI results are illustrated on the right side of the figure (above), in addition to being described below.
To the prerequisite question (“Do empirical observations align with theoretical claims?”) we answer yes.
Going through the 7 EQI criteria:
1) 800 participants were included, so S1=100*(800/1000) = 80
2) it’s a randomized controlled trial, which is the current best practice for causal claims (S2=100)
3) there’s a control group (individuals who used an alternative strategy) (S3=100)
4) there was accounting for potential confounds, such as the confound of the passage of time (hiccups could go away on their own), in the form of participants recording hiccup start and stop times and inclusion of that information in the statistical modeling (S4=100)
5) the sample was fairly representative, matching Study A’s (S5=75)
6) results were replicated within the study (starting with 400 subjects as discovery dataset, replicating in remaining 400 subject dataset) (S6=100)
7) results were corrected for multiple comparisons using permutation testing (S7=100)
Study B’s EQI: (80+100+100+100+75+100+100)/7 = 93.6
What can we learn from these examples?
First, I think these examples make it clear that developing a useful EQI is possible.
Comparing Study A’s EQI of 27.1 to Study B’s EQI of 93.6 makes it clear that Study B’s empirical findings are much better supported. The radar plots in the figure (above) give a visual indication of why one study’s EQI value was higher than the other. This would lead one to conclude that there’s much better evidence that “rapidly drinking an entire 8 oz of water at once with a straw” cures hiccups than the alternatives tested – the empirical conclusion of Study B (not Study A).
Second, the semi-arbitrariness of some sub-scores (e.g., criterion #1, sample size) show how important the versioning system would be for keeping up with best practices. And of course it will be difficult to get consensus on best practices for updating the EQI criteria. The 1000 participant ideal/best practice is beyond the kind of data I could collect in my own small lab, so I balked at that number, but several large behavioral and neuroimaging datasets go to that number and beyond (e.g., the Human Connectome Project). And of course each scientific field and type of data will have its own best practice here. I can imagine EQI values being updated retrospectively for studies (along with the associated EQI version number) as best practices evolve due to better methods development and validation.
Third, considering alternatives to these examples made it clear that it would be very difficult to extend the EQI to quantify evidence for a specific hypothesis – as opposed to an empirical claim. I chose these examples partly because the mapping between empirical claim and hypothesis was clean, but that is often not the case.
For example, I may hypothesize that the amygdala (a brain region) is essential for experiencing humor, but I may use an imperfect (but currently the best for answering this question in healthy humans) brain imaging method like fMRI to test that hypothesis. The empirical claim would be something like: “presenting participants with sentences that they report as humorous increases fMRI activity in the amygdala more than sentences they report as not humorous”. That claim would receive an EQI score, rather than the hypothesis directly, since fMRI does not conclusively reveal the necessity of a part of the brain for a given function. The EQI prerequisite (“Do empirical observations align with theoretical claims?”) also helps here, since this should push the authors to make it clear that their hypothesis was supported but further research would be needed to show the necessity of amygdala for humor.
Current problems with the EQI
It’d be helpful to receive ideas for potential problems with this EQI draft in the comments section.
Here are some problems I see (which can hopefully be corrected with time!):
The EQI is likely overfit to my area of research (for now), which is human neuroscience and psychology. Most importantly, it will be critical to figure out how to set the sample size score (EQI criterion #1) for a wide variety of scientific fields.
Could readers (scientists and non-scientists) become too reliant on the EQI, failing to consider a study’s complex logic before deciding whether to believe the study’s conclusions? I think this is a real risk of the EQI. However, I think it is worth this risk, since most readers probably don’t do this anyway. This is likely because readers lack the time and cognitive resources necessary to read each study carefully. The EQI can help with this problem by lowering the time and cognitive effort necessary to get a valid (while imperfect) estimate of study quality.
Could the EQI ever help establish large diffuse theories like evolution by natural selection? I’m thinking it could help solidify the observations that support the theory, but since (with the possible exception of some artificial selection experiments) we do not have the ability to perform causal experiments to test evolution it could appear that there is only limited evidence for evolution. This follows from most evolution-supporting studies being observational, and therefore receiving relatively low EQI values. Clearly science needs room for diffuse individually-weak evidence for a theory that nonetheless strongly supports that theory in aggregate! Is there a way to make the EQI compatible with this?
Could strongly valuing the EQI draw scientists toward easy-to-prove findings, since high EQIs would be easier to attain? I think this would be a problem for EQI if it is used in isolation. If the EQI is used in combination with citation counts this should be less of an issue.
Could strongly valuing the EQI push scientists away from important exploratory and preliminary studies? I hope not, since we should be strongly valuing the importance of a study beyond its conclusiveness. If a study is very preliminary – due to lack of resources or lack of good methods in that area – but the topic is very important, then we should value it despite a low EQI. In such a case a low EQI would indicate that more research is needed in this important area!
Science is extremely complex, and reality (the target of science) even more so. How can a single number summarize the strength of evidence provided by even one complex study, let alone all of them? I think there will need to be a calibration period for the EQI for each scientific field to ensure EQI values match up with expert opinions. And of course readers will need to be educated regarding what the EQI does and does not quantify.
Ideally, rather than just applying to a single study, an EQI could also be applied to each finding that accumulates evidence across multiple studies. It’s unclear to me exactly how to do this, but it could be considered a meta-analysis tool. Each study would modify the cumulative EQI quantifying the quality of the evidence supporting a given empirical claim.
Who should decide each study’s EQI?
There are many options here, with two main issues. First, who will be motivated enough (and have enough resources) to go through the work of calculating EQI values for each study? Second, who will be unbiased enough to calculate (or verify) EQI values accurately?
I’m thinking authors should calculate their own EQI value (they have the motivation and knowledge to calculate it), with peer reviewers verifying that the EQI value is accurate (they should be less biased toward inflating EQI values).
Ideally there would also be a central database of EQI values verified by peer review, as well as EQI values for previous studies verified by the scientific community. I’m hoping to explore options for this idea in future posts.
I’m unsure who should decide the EQI criteria, especially field-specific criteria (e.g., sample size). I’m thinking there’d ideally be a group of scientists that sets the EQI, with representatives from each field of science. (Let me know if you’d be interested in being included in such a group.)
Conclusions
Broad implementation of an EQI assigned to each scientific study would have many benefits.
For scientists, an EQI could shift the incentive structure toward improving the quality of reported evidence. Further, having an EQI with each study would help with scientific article curation, reducing the burden of assessing study quality when deciding whether to read a paper and when deciding whether to consider the study’s results as preliminary or conclusive.
For non-scientists (and scientists in other fields), broad use of EQI would help with determining the quality of a study even when the methods are not well understood. This would be immensely helpful for deciding whether to believe each study’s conclusions. Of course, nothing beats expert understanding of an area of science, but a properly calibrated and implemented EQI would be invaluable to non-experts for making sense out of scientific studies.
There are certainly issues to be worked out with this preliminary EQI plan. But working it through here has convinced me that it will be possible to eventually get this working.
Before comments on content per se I'd argue that you should call this 'Evidence of Article Quality Index' my main point being that an article is not necessarily the result of 'a' study, sometimes a study have to be sliced sometimes they are sliced but should not (maybe another criteria to include ... )
OK let's get to it ... I agree with two out of the three premises (1) tool against science misinformation especially for general public and media and (2) this could improve the incentive structure for scientists by giving them quantifiable credit for the quality of their work. I can see a problem related to scientific literature curation: no one reads low EAQI articles, yet these can contain completely new and revolutionary ideas? then what we miss out of that .. or should those get a boost? hard to judge.
A word on replication as criteria: I'm guessing you are talking about direct replication, but how should one do it? if significant result in study one, power is 100% (prob to have a + results --https://www.vims.edu/people/hoenig_jm/pubs/hoenig2.pdf) so should we redo with same sample size anyway? or a priori collect and split data? establishing criteria will be hard, but not impossible (see generics)
A word on 'fully established' --> in my mind it has to do with cumulative evidence from conceptual replication ; even so a single study with many substudies as controls for many possible biases or explanations for instance (i.e. systematic replications) seems as credible or maybe more than a study with a direct replication (again establishing those criteria).
Last but not least, we need to experiment and provide evidence ... how many rater are needed to have a stable score? :-)
Cyril